1.变量
chr与ord函数- 变量实际是一个对象的引用
print(r ' string ' )中的\会完整输出- 变量包括三个属性
id(内存地址),type,value - 二进制前缀
0b,八进制前缀0o,十六进制前缀0x - 转二进制函数
bin(),结果是字符串类型 - 转八进制函数
oct(),结果是字符串类型 - 转十六进制函数
hex(),结果是字符串类型
2.数据类型
- 三引号
'''或"""字符串可以多行显示,也可用来进行注释 bool类型可以化为整型- 类型转换:
str(),int(),float() - 一个变量的type属性可以变化:
a=int(a)
3.输入与运算符
present=input("提示语句"),运行结果是string类型算术运算符
- 除法运算
/(结果是float类型),整除运算//(一正一负向下取整数) - 取余运算
% - 幂运算
**
- 除法运算
赋值运算符
运算顺序从右到左
支持链式赋值
a=b=c=10,三者id相同,即地址相同,亦即只创建了一个内存对象支持参数复制
支持系列解包复制
a,b,c=20,30,40,创建了三个内存对象a,b=b,a,交换值
比较运算符
- 运算结果是
bool类型 ==比较的是valueis与is not比较的是id
- 运算结果是
布尔运算符
and,or,not,in,not in
位运算符
&,|,>>,<<
运算符的优先级
- 算术运算符——位运算符——比较运算符——布尔运算符——赋值运算符
- 位运算符:<<,>> & |
- 布尔运算符:and or
4.程序的组织结构
顺序结构,选择结构,循环结构
python一切皆对象,所有对象皆有一个布尔值
- 获取对象的布尔值,使用内置函数
bool() - 以下对象的布尔值为
false,其他均为true- False
- 数值0
- None
- 空字符串
- 空列表
- 空元组
- 空字典
- 空集合
- 获取对象的布尔值,使用内置函数
选择结构
if 条件表达式:- 多分支
if-elif - 条件表达式
90<=num<=100 print((num_a,'大于等于',num_b) if num_a>=num_b else (num_a,'小于',num_b))- 如果是true则输出前面内容,是false则输出后面内容
pass什么都不做,只是一个占位符
循环结构
- 内置函数range
- 用于生成一个整数序列
(range对象),迭代器 - 创建range对象三种方式
range(stop)创建一个(0,stop)之间的整数序列,步长为1range(start,stop)range(start,stop,step)print(list(r))用于查看range对象中的整数序列
- range对象的优点:只存储三个值,占用内存空间较少,只有当用到range对象时,才回去计算序列中的相关元素
- 用于生成一个整数序列
while循环while 条件表达式:
for-in循环for i in 可迭代对象:- 如果在循环体中不需要使用自定义变量,可将自定义变量写为
_
else与for和whilefor与while正常执行完毕退出后执行else语句,但当遇到break时,不执行else语句
- 内置函数range
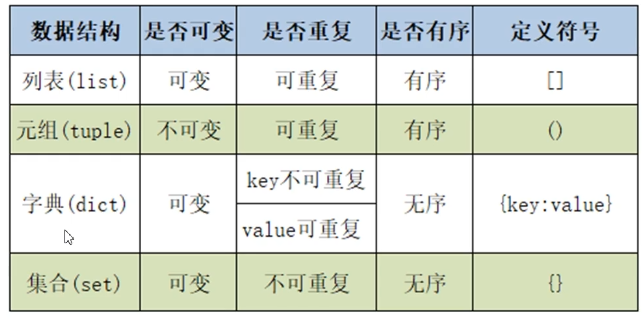
5.列表
列表相当于其他语言中的数组,可对其中的数据进行整体操作
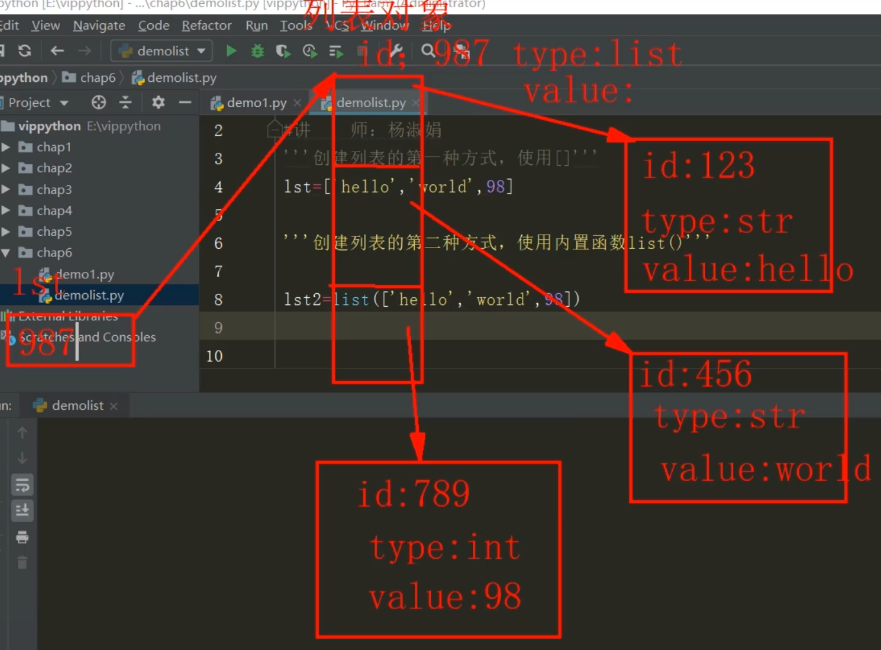
lst=['hello','world',98]列表是n多个引用,存储的是对象的引用,即对象的
id,上述列表的的三个引用指向列表对象列表的创建:
- 使用中括号
[] - 使用内置函数
list([])
- 使用中括号
列表的特点:
- 列表元素按照顺序有序排列
- 索引映射唯一的一个元素
- 可以存储相同数据
- 任意数据类型
- 根据需要动态分配回收内存,不用担心多和不够用
列表的操作
lst.index(),获取列表中元素的索引- 如果有相同元素返回较小的索引
lst.index(element,a,b),在指定的**[a,b)**中查找元素的索引
获取列表的多个元素——切片
lst[a:b:c],切片是一个新的列表对象,从a开始到b结束,步长为c- 步长为负数时,逆序输出,
start从末尾开始,stop从开头开始
判断指定元素在列表是否存在
in与not in
列表元素的增删改
——增加
list.append()在列表的末尾添加一个元素lst.append(lst2)是将lst2作为一个元素添加lst.extend(lst2)将lst2中的元素追加到lst中lst.insert(a,b)在a位置添加一个元素blst[a:]=lst2将lst[a:]部分替换为lst2——删除
lst.remove(elemrnt)在列表中移除元素element,多个元素只移除一个lst.pop(index)根据索引移除元素,若不指定索引则删除最后一个元素lst[a:b]=[]用空列表替代,删除多个元素lst.clear()清除列表中的所有元素del lst删除lst——修改
通过索引修改
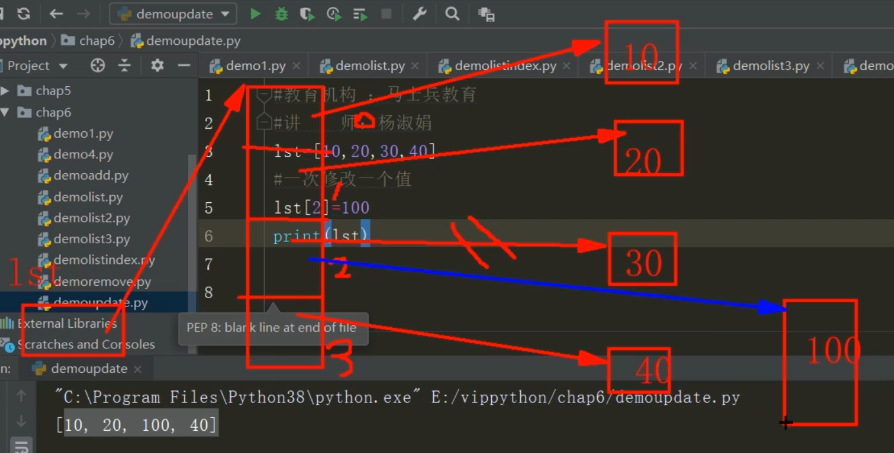
lst[a:]=lst2将lst[a:]部分替换为lst2
列表的排序操作
lst.sort(),升序排序list.sort(cmp=None,key=None,reverse=False)cmp可选参数,如果指定了该参数会使用该参数的方法进行排序key主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序#获取列表的第二个元素 def takeSecond(elem): return elem[1] #列表 random=[(2,2),(3,4),(4,1),(1,3)] #指定第二个元素排序 random.sort(key=takeSecond) #输出类别 print(random)上例中的
takeSecond()常用lambda函数实现takeSecond = lambda elem : elem[1]
lst.sort(reverse=True),降序排序lst.sorted(),产生一个新的列表对象
列表生成式
- 即生成列表的公式
lst=[f(i) for i in range(1,10)],则列表中的元素是f(i)
字典
字典是python内置的数据结构之一,与列表一样是一个可变序列,以
{}表示,以键-值对方式存储数据列表是一个有序的序列,字典是一个无序序列,位置由hash决定
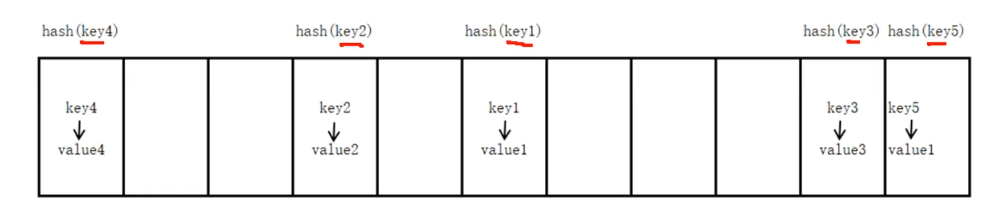
放在字典中的键必须是不可变序列(如字符串,整数),即不可进行增删改操作
字典的创建
scores={'张三':100,'李四':80}- 使用内置函数
dict(),stduent=dict('name'='jack','age'=20)
字典中元素的获取
尽量使用
get函数scores['张三']使用内置函数
get(),scores.get('张三')索引查找不存在时报错,
get()函数查找不存在时返回none或默认值scores.get('陈六',00),其中00即是默认值
字典的增删改
- 键的判断:
in或not in - 键值对的删除:
del scores['张三'] - 字典的清空:
dict.clear() - 键值对的添加或修改:
dict['陈六']=50
- 键的判断:
获取字典的视图
- 获取字典中所有的key:
dict.key() - 获取字典中所有的value:
dict.value() - 获取字典中所有键值对:
dict.items() - 上述函数返回的是
dict_key,dict_values,dict_items类型,一般要进行list()转换
- 获取字典中所有的key:
字典元素的遍历
for item in dict: print(item,dict[item])
字典的总结_特点
- 键不允许重复,否则会覆盖,值可以重复
- 字典中的元素是无序的
- 字典会浪费大量的内存,是用空间换时间
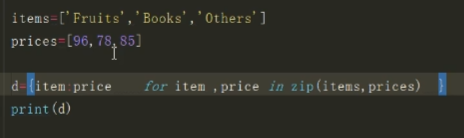
字典生成式

元组与集合
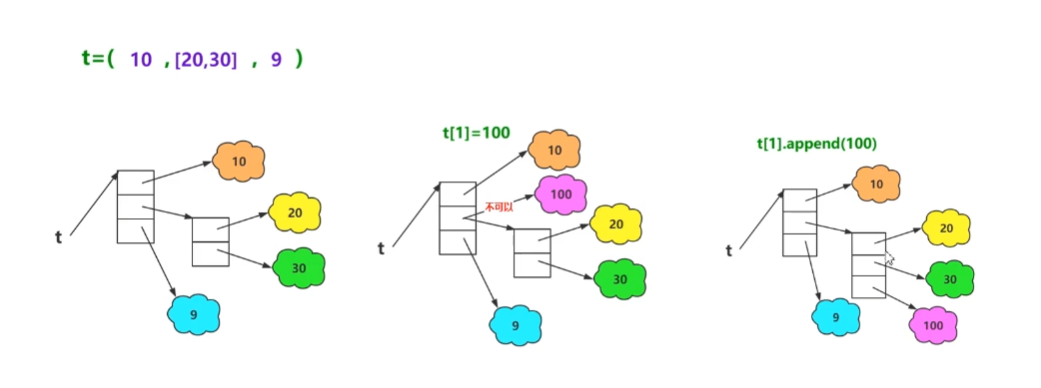
元组
- 元组是python内置的数据结构之一,属于不可变序列,其他与
list类似 - 元组的创建方式
- 使用
():t=('python','world',98) - 使用内置函数
tuple:t=tuple(('python','world',98)) - 元组只有一个元素时要加上
,
- 使用
- 元组设计成不可变序列的原因
- 在多任务环境下,同时操作对象时不需要加锁
- 元组的遍历
- 使用索引获取
- 使用
for循环遍历
集合
- 集合是python语言提供的内置数据结构,输入可变类型序列,支持增删改操作
- 集合是没有value的字典,底层函数也使用了hash表,集合同样不允许重复,元素无序
- 集合的创建
s={'a','b'}- 内置函数
set():set(range(6)) - 空集合:
s=set{} 
- 集合的相关操作
- 判断存在:
in和not in - 集合元素的新增操作
s.add(element),添加元素elements.update(),括号中可以放一个集合,列表,元组
- 集合元素的删除操作
s.remove(element),删除元素element,元素不存在会抛异常s.descard(element),删除元素element,元素不存在不会抛异常s.pop(),任意删除一个元素s.clear(),清除所有元素
- 集合之间的关系
- 判断集合相等:
==&!= - 判断子集:
s.issubset(s2),判断s是否是s2的子集 - 判断超集:
s.issuperset(s2) - 判断交集:
s.isdisjoint(s2)
- 判断集合相等:
- 集合的数据操作
- 交集:
s1.intersection(s2),或s1 & s2 - 并集:
s1.union(s2),或s1 | s2 - 差集:
s1.difference(s2),或s1-s2 - 对称差集:
s1.symmetric_difference(s2),或s1^ s2
- 交集:
- 判断存在:
- 集合生成式
set={f(i) for i in range(num)},类似于列表生成式
总结
6.字符串
- 字符串是python中的基本数据类型,是一个不可变序列
- 字符串驻留机制
- 仅保存一份相同且不可变字符串的方法,不同的值被保存在字符串的贮留池中,python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时,不会开辟新的空间,而是把该字符串的地址赋给新创建的变量
- 驻留机制的几种情况(交互模式)
pycharm对字符串优化处理
- 字符串的查询操作
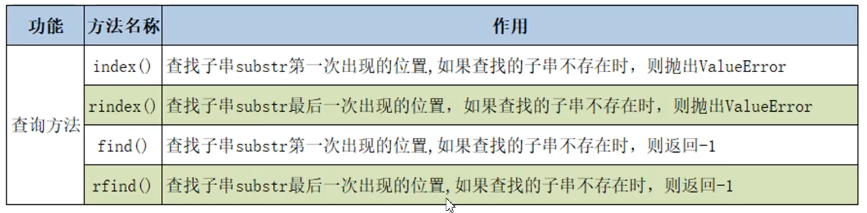
- 尽量使用
find方法
- 字符串的大小写转换
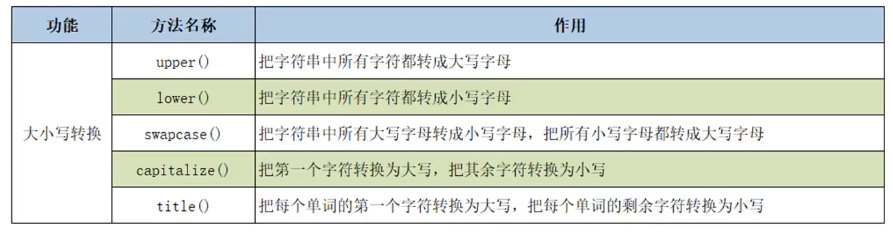
- 转换会产生一个新的字符串对象
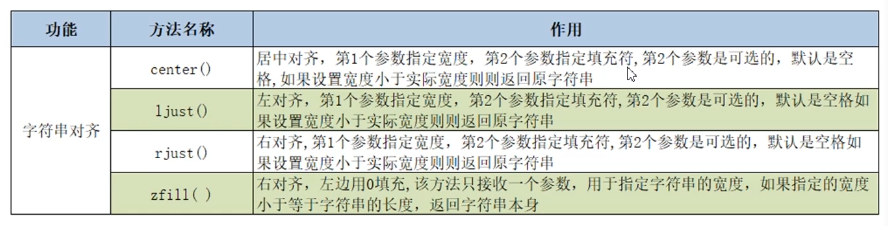
- 字符串的内容对齐操作
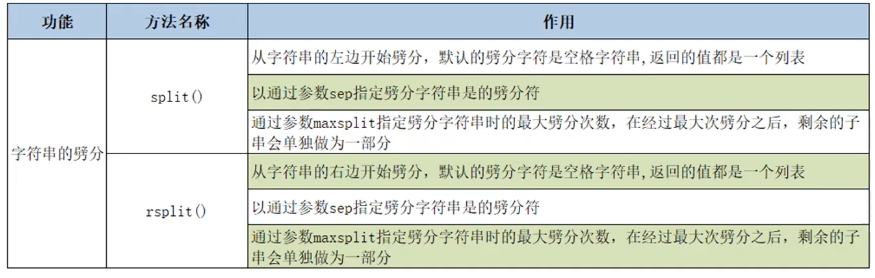
- 字符串的分割操作
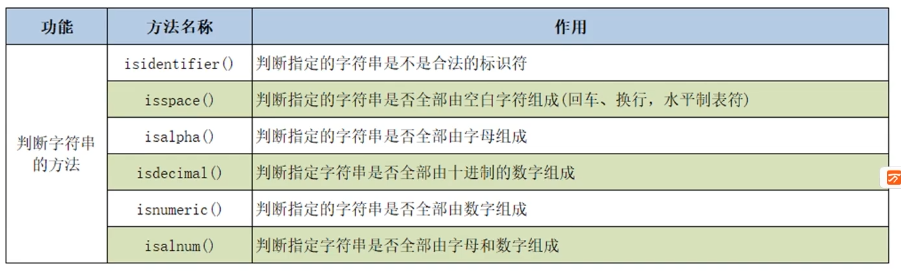
- 字符串的判断操作
- 字符串的替换与合并

pritn('x'.join(lst)),x是字符串的连接符print('*'.join('python'))的结果是p*y*t*h*o*n
- 字符串的比较操作
- 运算符
>,>=,<,<=,==,!= - 比较规则:有限比较两个字符串的第一个字符,如果相等则继续比较下一个字符,依次比较下去,知道两个字符串中的字符不相等时,其比较结果就是两个字符串的比较结果,两个字符串中的所有后续字符将不再被比较
- 运算符
- 字符串的切片操作
- 切片后产生新的对象
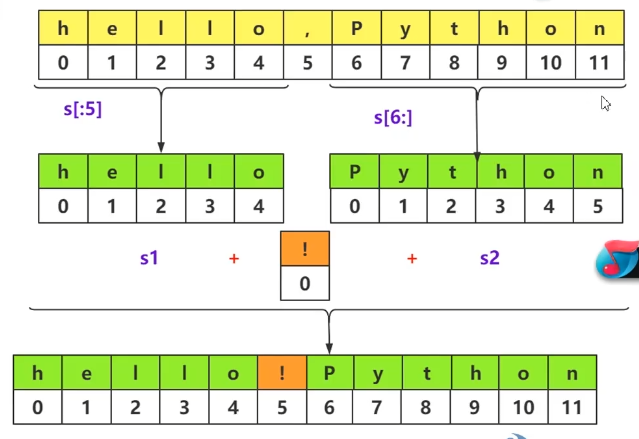
- 完整写法
s[statr:stop:step] - 与列表的切片类似
- 当
step是负数时会反序输出
- 格式化字符串(print)
- 原因:字符串中有些东西可变,有些东西不可变
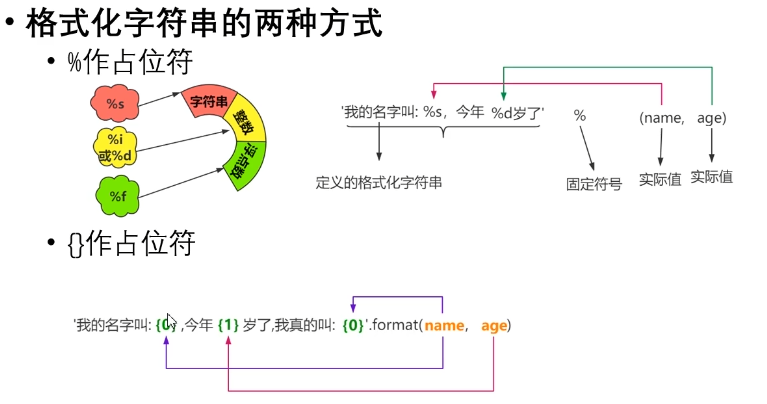
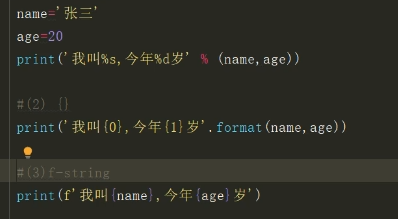
format字符串格式化,可以把format中的内容,放入到字符串指定位置- 第一种方式的精度与宽度设置类似于C语言
- 第二种:

- 字符串的编码转换
- 编码:将字符串 转换为二进制数据(
bytes) - 解码:将
bytes类型的数据转换成字符串类型 - 编码:
s.encode(encoding='GBK/UTF-8') - 解码:
byte.decode(encoding='GBK/UTF-8'),byte是编码出的二进制数据
- 编码:将字符串 转换为二进制数据(
- 总结
7.函数
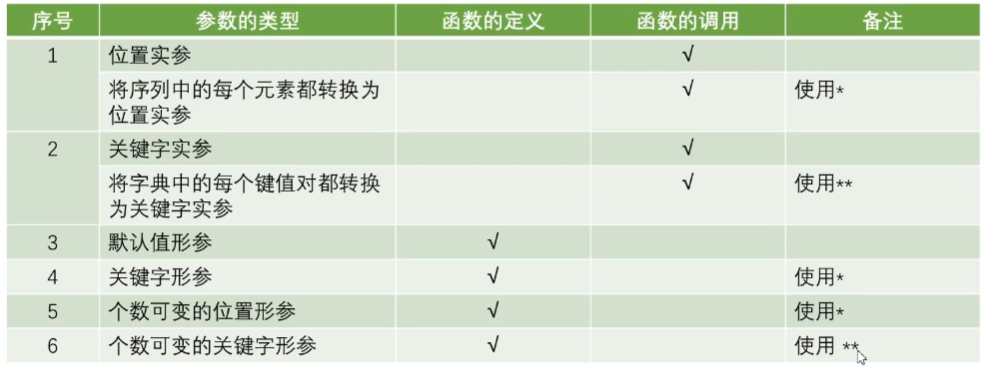
def 函数名([输入参数]) 函数体 [return xxx]输入参数可以通过
形参=实参进行指定可变类型变量和不可变类型变量传入函数后,前者可直接对实参修改,后者不可对实参修改
函数返回多个值时,结果是元组
函数定义时,给形参设置默认值,只有与默认值不符的时候才需要传递
定义参数时,可能无法事先确定传递的位置实参的个数
- 使用可变的位置参数,使用
*定义个数可变的位置形参,结果为一个元组,只能定义一个 
- 使用可变的关键字形参,使用
**定义个数可变的关键字传参,结果为一个字典,只能定义一个 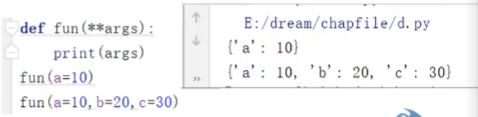
- 两者均出现时,要先写位置参数,再写关键字形参
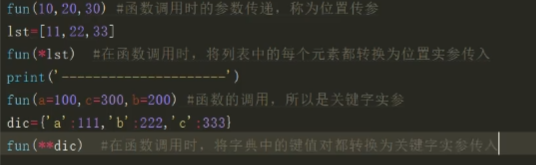
def fun(a,b,*,c,d)在*之后只能采用关键字传参
- 使用可变的位置参数,使用
函数参数总结
8.Bug
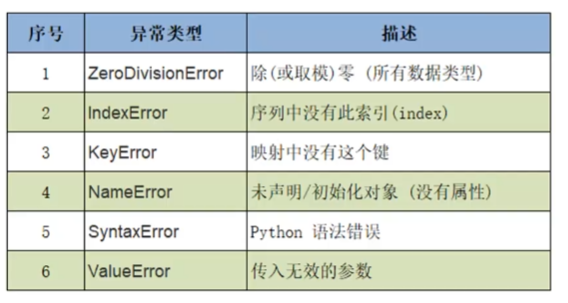
如果没有异常处理机制,则
bug由python自己捕获,如果有异常处理机制,则bug由处理机制捕获python的异常处理机制try-excepttry: ...可能出现异常的代码 ... except xxx: ... ... except yyy: ... ...xxx是捕获的异常
python异常处理机制try-except-else- 如果
try块中没有抛出异常,则执行else块,如果try中抛出异常,则执行except块 
- 如果
python异常处理机制try-except-else-finallyfinally块无论是否发生异常都会被执行,常用来释放try块中申请的资源
python的常见的异常类型traceback模块- 使用
traceback模块打印异常信息
- 使用
raise手动抛出异常try: score=int(input('请输入分数')) if 0<=score<=100: print('分数为',score) else: raise Exception('分数不正确') except Exception as e: print(e)
9.类与对象
类的创建
class Student:(首字母大写) pass
类的组成
- 类属性
- 实例属性
- 实例方法
- 静态方法
@staticmethod - 类方法
@classmethod 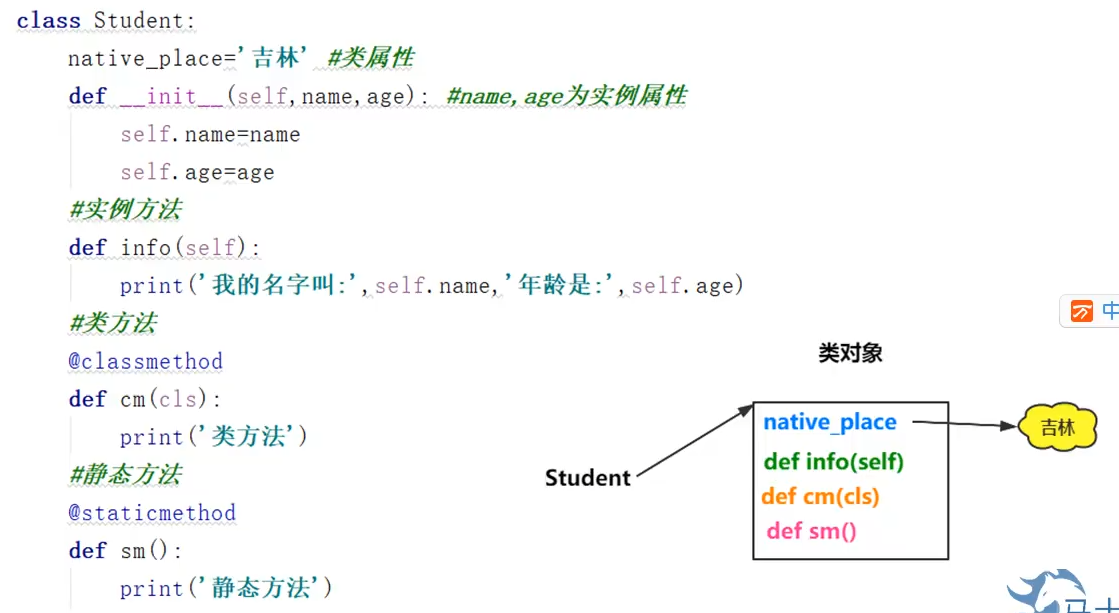
def在类之内定义的称为方法,在类之外的称为函数
对象(实例)的创建
实例名=类名()
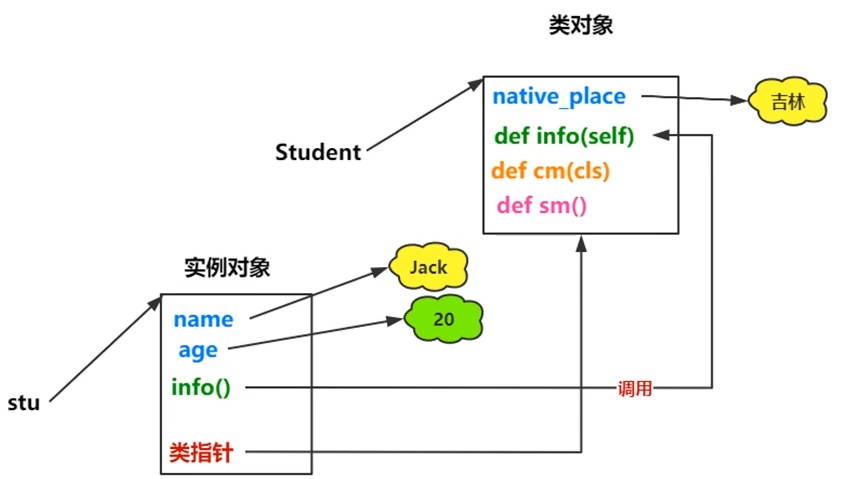
类属性,类方法与静态方法
dir()内置函数查看类对象的属性和方法类属性
对应于实例属性
类属性存储在类对象中,如果改变则所有实例对象的类属性都会同时更改,即被该类的所有对象所共享
实例对象通过类指针访问类属性
类方法
- 对应于实例方法
- 使用类名直接访问
静态方法
- 使用类名直接访问
动态绑定属性和方法
python语言是动态语言,在创建对象后,可以动态的绑定属性和方法def show(): print('我是一函数') stu=Student('Jack',20) stu.gender='男' # 动态绑定性别 print(stu.name,stu.age,stu.gender) stu.show=show() # 动态绑定方法 stu.show
10.面向对象
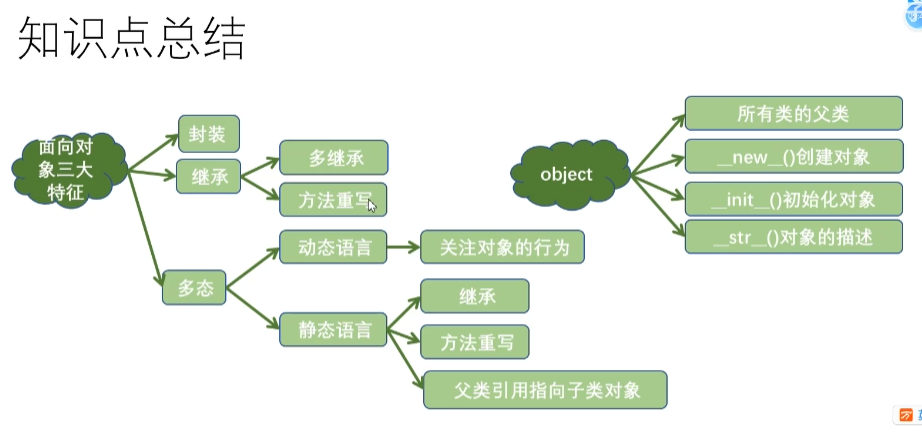
面向对象的三大特征
封装:提高程序的安全性
将数据(属性)和行为(方法)包装到类对象中。在方法内部对属性进行操作,在类对象的外部调用方法。这样,无需关心方法内部的具体实现细节,从而隔离了复杂度
在
python中没有专门的修饰符用于属性的私有,如果该属性不希望在类对象外部被访问,前边使用两个_class Student: def __init__(self,name,age): self.name=name self.__age=age # 年龄不希望在类的外部被直接使用 def show(self): print(self.name,self.__age)强迫访问
print(stu._Student__age)
继承:提高代码的复用性
class 子类类名(父类1,父类2): pass如何一个类没有继承任何类,则默认继承
objectpython支持多继承定义子类时,必须在其构造函数中调用父类的构造函数
class Person(object): def __init__(self,name,age): self.name=name self.age=age def info(self): print('姓名:{0},年龄:{1}',format(self.name,self.age)) # 定义子类 class Student(Person): def __init__(self,name,age,score): super().__init__(name,age) # 调用父类的构造函数 self.score=score # 测试 stu=Student('Jack',20,'100') stu.info方法重写
- 如果子类对继承自父类的某个属性或方法不满意,可以在子类中对其进行重新编写
- 子类重写的方法中可以通过
super().xxx()调用父类中被重写的方法
多态:提高程序的可扩展性和可维护性。动态语言多崇尚“鸭子类型”,当一只鸟走起来像鸭子、游泳起来像鸭子,那么这只鸟就可以被称为鸭子,不关心对象的类型只关心对象的行为。
简单的说,多态就是“具有多种形态”,它指的是:即便不知道一个变量所引用的对象到底是什么类型,仍然可以同个这个变量调用方法,在运行过程中根据变量所引用对象的类型,动态决定调用哪个对象中的方法
class Animal(): def eat(self): print('动物要吃肉') class Dog(Animal): def eat(self): print('狗吃肉') class Cat(Animal): def eat(self): print('猫吃鱼') class Person(): def eat(self): print('人吃五谷杂粮')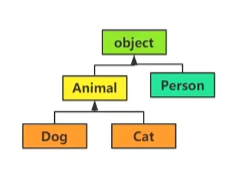
def fun(obj): obj.eat() fun(Dog()) fun(Cat()) fun(Person())三种调用方法均不报错,判断条件只是调用的对象是否有eat()方法
object类print(stu)调用的是object父类中的__str__()方法,可以对其进行重写来改变print(stu)的输出def __str__(self): return '我的名字是{0},今年{1}岁'.format(self.name,self,age)
特殊的属性

x.__class__输出对象的所属的类C.__bases__输出C的父类C.__base__输出第一个父类C.__mro__输出类的层次结构A.__subclasses__输出所有子类
特殊的方法
- 类当中的
__add__()方法相当于+ - 类当中的
__len__()方法相当于len()
- 类当中的
__init__()和__new__()__init__()方法用于初始化__new__()方法用于创建对象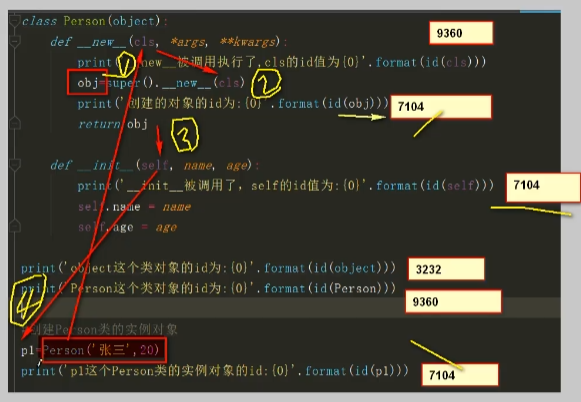
类的赋值和浅拷贝
类的赋值操作,使得两个对象
id相同python拷贝一般都是浅拷贝,拷贝时对象包含的子对象内容不拷贝,因此源对象与拷贝对象会引用同一个子对象class CPU: pass class Disk: pass class Computer: def __init__(self,cpu,disk): self.cpu=cpu self.disk=disk cpu1=CPU() disk=Disk() computer=Computer(cpu1,disk) import copy computer2=copy.copy(computer) print(computer,computer.cpu,computer.disk) print(computer2,computer2.cpu,computer2.disk)其中
computer和computer2指向的子对象都是cpu1和disk
深拷贝
- 使用
copy模块的deepcopy函数,递归拷贝对象中包含的子对象,源对象和拷贝对象对所有的子对象也不相同
- 使用
总结
11.模块
一个
.py文件就是一个模块将一个
python程序分成几个模块开发使用模块的好处
- 方便其他程序和脚本的导入并使用
- 避免函数名和变量名的冲突
- 提高代码的可维护性
- 提高代码的可重用性
自定义模块
- 创建模块
- 新建一个
.py文件,名称尽量不要与python自带的标准模块名称相同
- 新建一个
- 导入模块
import 模块名称 [as 别名]from 模块名称 import 包/模块/函数/变量/类
- 创建模块
以主程序(以主函数)形式运行
导入自定义包的时候,会执行导入包的程序内容
使用
if __name__=='__main__': pass后,当此包被导入后不会执行程序(即pass的内容)。
python中的包- 包是一个分层次的目录结构,它将一组功能相近的模块组织在一个目录下
- 作用
- 代码规范
- 避免模块名称冲突
- 包与目录的区别
- 包含
__init__.py文件的目录称为包 - 目录里通常不包含
__init__.py文件
- 包含
- 包的导入
import 包名.模块名
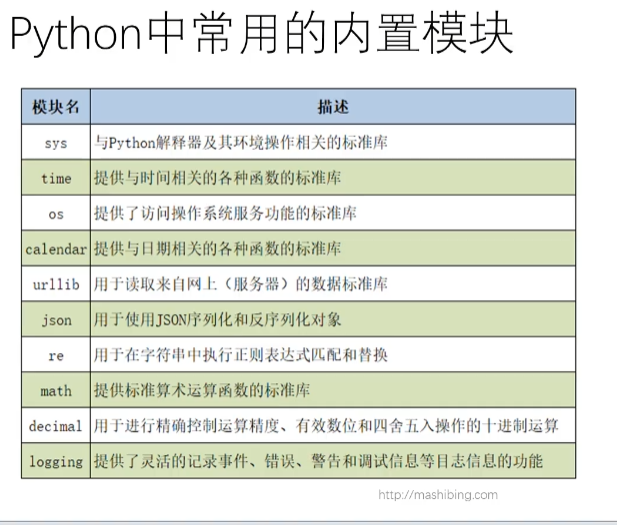
python中常用的内置模块第三方模块的安装与使用
cmd界面pip install 模块名impot 模块名
12.文件操作
编码格式
- 常见的字符编码格式
python的解释器使用的事Unicode(内存).py文件在磁盘上使用UTF-8存储(外存)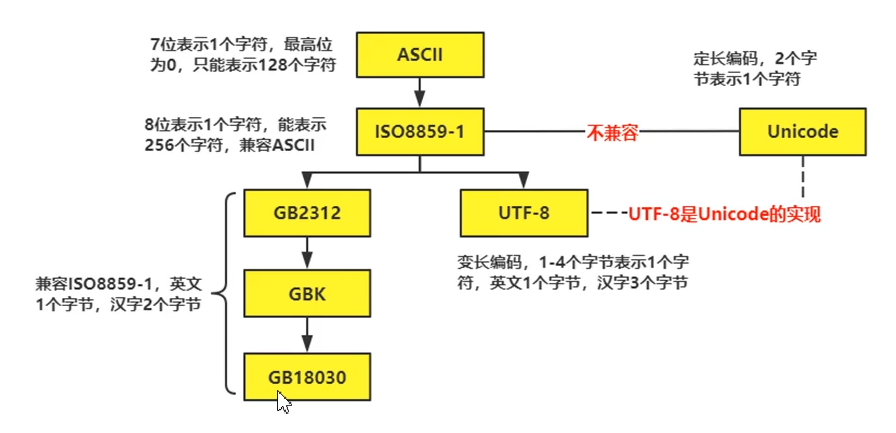
- 常见的字符编码格式
文件的读写原理
文件的读写俗称“IO操作”
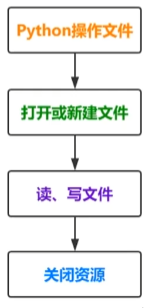
文件操作流程
内置函数
open()创建文件对象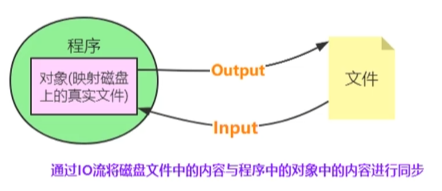
语法规则
file=open(filename[,mode,encoding])mode打开模式默认为只读,默认文本文件的编码格式为gbk
常见的文件打开模式
按文件中数据的组织形式,文件分为以下两大类
文本文件:存储的事普通“字符”文本,默认为
unicode字符集,可以用记事本程序打开二进制文件:把数据内容用“字节”进行存储,无法用记事本打开,必须使用专用的软件打开,举例:
mp3音频文件,jpg图片,doc文档等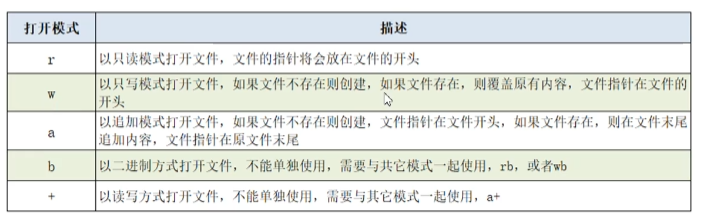
src_file=open('logo.png','rb') dest_file=open('logo_2.png','wb') dest_file.write(src_file.read()) src_file.close() dest_file.close()
文件对象的常用方法
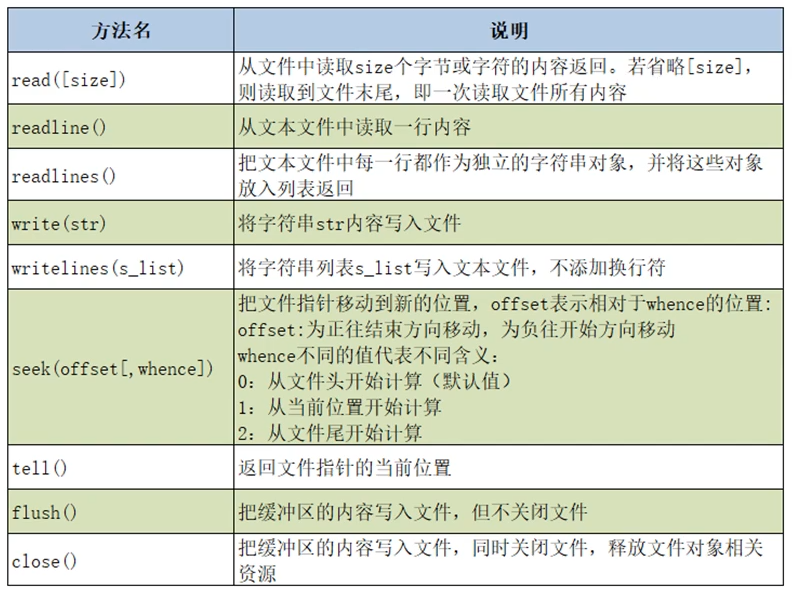
file=open("123.txt",'r') file.seek(2) print(file.read()) print(file.tell()) print(file.read()) file.seek(0,0) print(file.read()) file.close()
with语句(上下文管理器)with语句可以自动管理上下文资源,不论什么原因跳出with块,都能确保文件正确的关闭,以此来达到释放资源的目的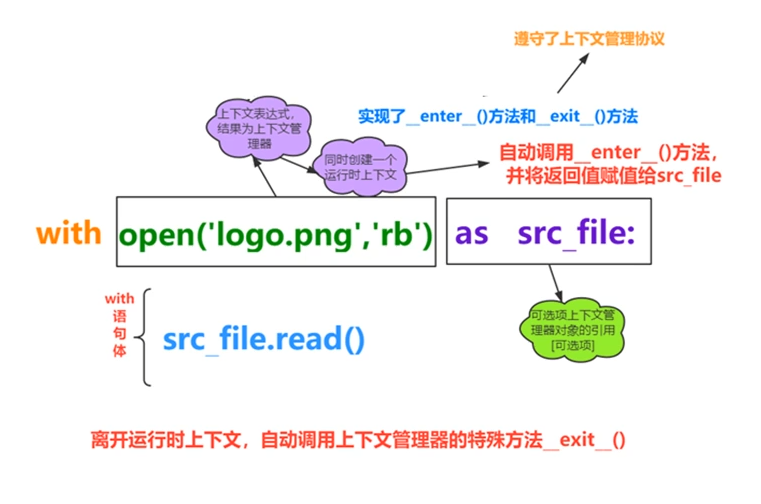
with open('123.txt','r') as file: passwith open('logo.png','rb') as src_file: with open('logo_2.png','wb') as dest_file: dest_file.write(src_file.read())
目录操作
os模块是python内置的与操作系统功能和文件系统相关的模块,该模块中的语句的执行结果通常与操作系统有关,在不同的操作系统上运行,得到的结果可能不一样os模块与os.path模块用于对于目录或文件进行操作os模块os.startfile(str)打开exe文件os.system(cmd)在cmd窗口输入命令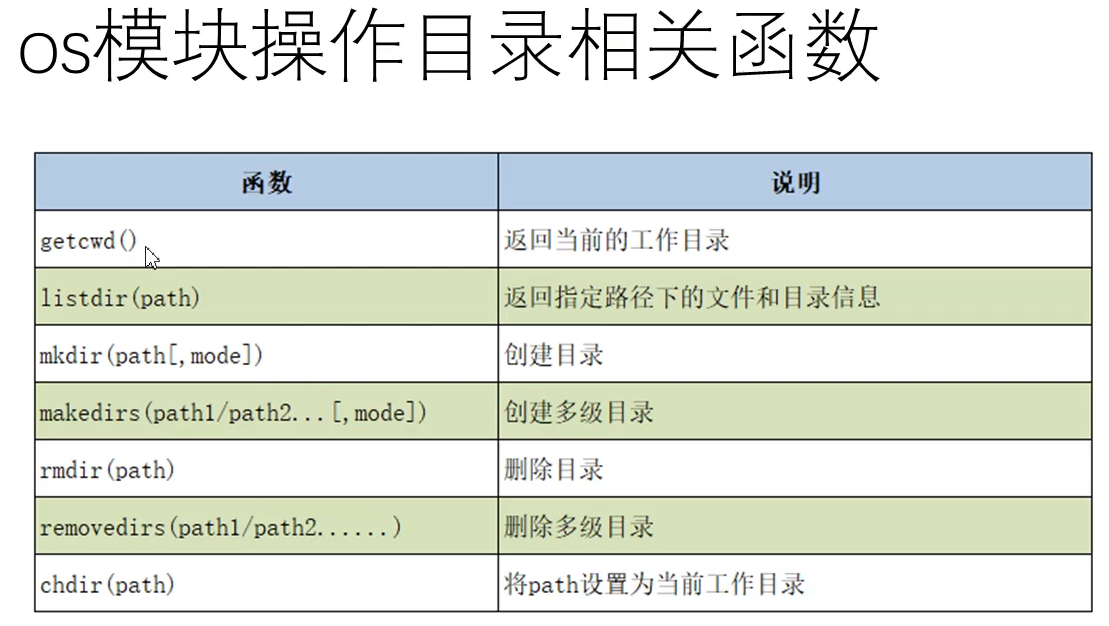
os.path模块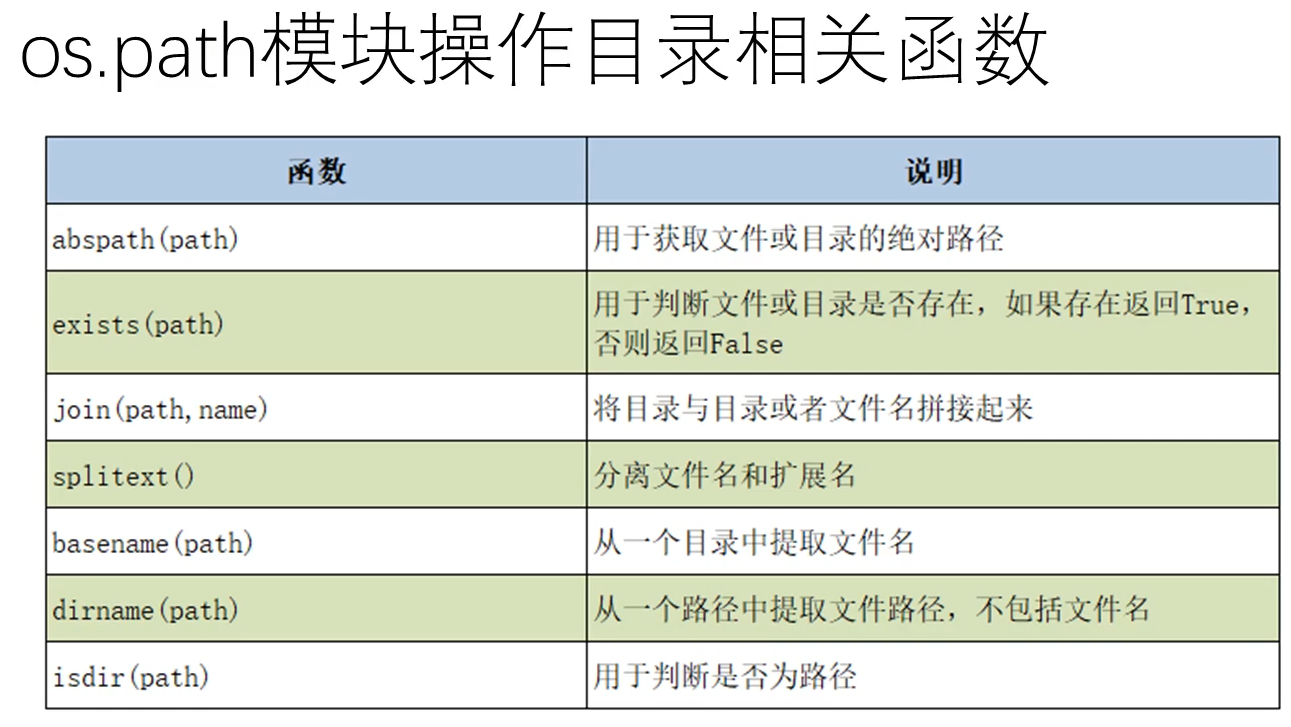
- 判断后缀时可以使用
filename.endwith(.py)函数,返回值是bool型
os模块中的walk()方法os.walk方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下返回多个三元组
(root,dirs,files)root指的是当前正在遍历的这个文件夹的本身的地址dirs是一个list,内容是该文件夹中所有的目录的名字(不包括子目录)files同样是一个list,内容是该文件夹中所有的文件(不包括子目录)import os path=os.getcwd() lst_files=os.walk(path) for dirpath,dirname,filename in lst_files: for dir in dirname: print(os.path.join(dirpath,dir)) for file in filename: print(os.path.jion(dirpath,file))
13.补充
eval函数
eval函数用来执行一个字符串表达式,并返回表达式的值。还可以把字符串转化为list,tuple,dict。eval函数的语法:eval(expression[,globals[,locals]])expression是表达式globals是变量的作用域,如果被提供,必须是一个字典对象locals是变量作用域,如果被提供,可以是任何映射对象
实例:
a='[1,2,3,4,5,6]' b=eval(a) #a是字符串类型数据,b是列表类型数据a='{'name':zhangsan,'age':25}' b=eval(a) #a是字符串类型数据,b是字典类型数据a='(1,2,3,4,5,6)' b=eval(a) #a是字符串类型数据,b是元组类型数据注意
eval函数会忽略一些字符,比如说\n
print语句中添加f
tensor=torch.rand(3,4) print(f"Shape of tensor:{tensor.shape}") # 这条语句等效于 print("Shape of tensor:{}".format(tensor.shape))
lambda函数用法lambda函数是一类无需定义标识符(函数名)的函数或子程序def sum(x,y): return x+y #上述代码相当于 sum = lambda x,y :x+y
项目打包为
exe可执行文件安装第三方模块
在线安装
pip intsall PyInstaller执行打包操作
pyinstaller -F D:\PyCharm\py\studentInfoSystem\main.py-F是指只生成一个可执行文件执行完毕后,
exe文件存放在倒数第二行的路径之中
设置输出字体颜色
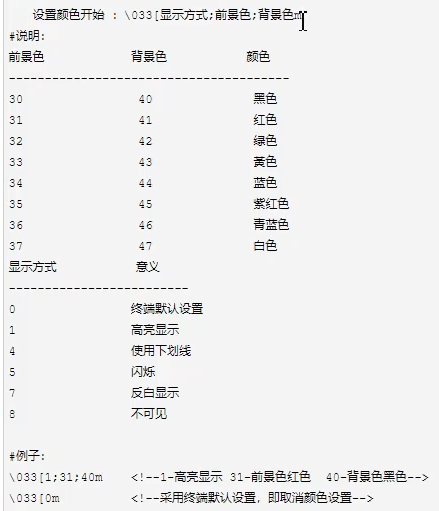
print('\033[0;35m\t\t图书音像勋章\033[m')夹在
\033[0;35m和\033[m之间的变色
enumerate函数用来获得列表数据及其索引
for index,value in enumerate(lst): pass使用
enumerate函数的原因是,用于修改列表中的值;如果不用index,那么修改的value仅是列表中值的拷贝
excel工具- 导入包
openpyxl wk = openpyxl.Workbook()创建工作簿对象sheet = wk.sheet获取活动表sheet.append(item)遍历列表,将列表中的数据添加到工作表中,表中的一条数据,在excel中是一行wk.save()保存
- 导入包

