爬虫
- 从本质上说,就是利用程序在网上拿到对我们有用的数据
- 实际上爬虫就是使用编程语言所编写的程序,作用是从网络上获取有价值的数据,重要的就是速度比手动获取数据快
爬取网页视频
使用
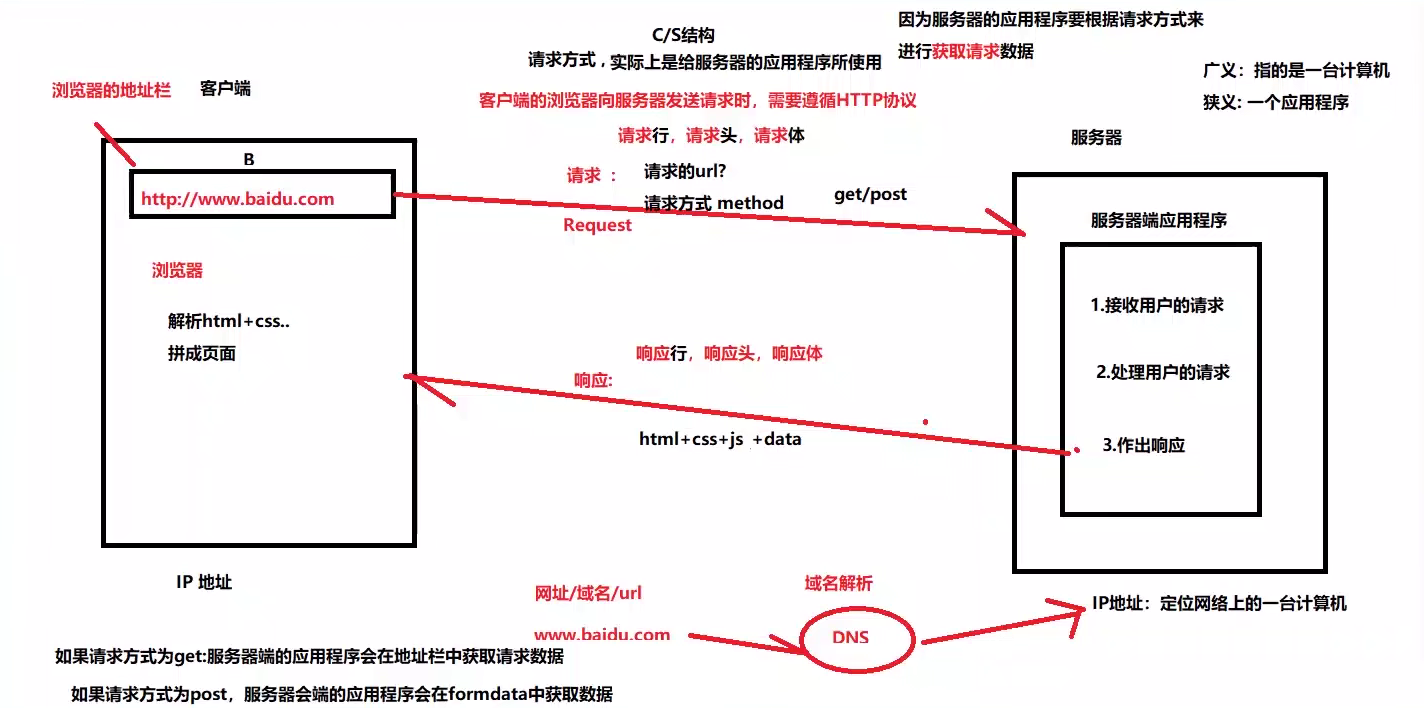
python程序替浏览器发请求,接收响应安装第三方软件
requests,使用pip install requestsimport requests url='https://www.baidu.com/' #请求的网址,请求的方式位get,所以使用request的get方法 resp=requests.get(url) print(resp) print(resp.request.headers)得到一个响应码,200表示成功,418表示遭到反爬
运行上述代码会得到
为防止被检测到,需要更改
UAimport requests url='https://www.baidu.com/' #请求的网址,请求的方式位get,所以使用request的get方法 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36 Edg/93.0.961.52'} resp=requests.get(url,headers=headers) print(resp)#请求响应码 print(resp.request.headers)#请求头得到

- 可防止初级的反爬
正则表达式
- 正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为”元字符”)。
- 正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
- ——》菜鸟教程
利用正则表达式提取
resp.text中的内容import requests import re#引入正则表达式 import time url='https://www.qiushibaike.com/video/' #请求的网址,请求的方式位get,所以使用request的get方法 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36 Edg/93.0.961.52'} resp=requests.get(url,headers=headers) #第一个参数为规则,第二个参数为查找的内容;“.”代表任意字符,“*”代表任意个 info = re.findall(r'<source src="(.*)" type=\'video/mp4\' />',resp.text) #info是列表 lst=[] for item in info: lst.append('https:'+item) #print(lst) #下载视频,一个一个发请求 count=0 for index,item in enumerate(lst): req=requests.get(item,headers=headers) print("第{0}个视频于{1}开始下载".format(index,time.asctime(time.localtime(time.time())))) count+=1 with open('video/'+str(count)+'.mp4','wb') as dir: #写入本地磁盘 dir.write(req.content) print("第{0}个视频于{1}下载结束".format(index,time.asctime(time.localtime(time.time()))))text和context- 前者是文本,后者是二进制文件

京东数据可视化分析
分析有效的
url,及数据的形式静态数据与动态数据
- 静态数据:服务器端已经渲染好的内容,直接发给浏览器,浏览器直接解释执行
- 动态数据:点击下一页,数据栏未发生变化,说明数据时后来被渲染到HTML中的
f12找到评论数据的请求,打开对应的url,复制信息到json.cn进行解析(注意去掉多的内容)
编写
python向服务器发送请求获取数据import requests import json import time import openpyxl #用于操作excel #获取评论 def getComment(productId,page): #发送请求 url='https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId={0}&score=0&sortType=5&page={1}&pageSize=10&isShadowSku=0&fold=1'.format(productId,page) headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36 Edg/93.0.961.52'} resp=requests.get(url,headers=headers) # if url==None: # print('爬取失败') # else: # print('爬取成功') #显示输出,去掉多余的 s=resp.text.replace('fetchJSON_comment98(','') s=s.replace(');','') #json解析 json_data=json.loads(s) return json_data #获取最大页数 def getMaxPage(productId): dic_data=getComment(productId,0)#向服务器发送请求,获取字典信息 return dic_data['maxPage'] #提取数据 def getInfo(productId): #max_page=getMaxPage() 不能爬取太多,否则会被封ip max_page=1 lst=[] #存储提取到的数据 for page in range(1,max_page+1): comments=getComment(productId,page) commentList=comments['comments'] #遍历列表,获取每条评论的内容,颜色,鞋码 for item in commentList: content=item['content'] color=item['productColor'] size=item['productSize'] lst.append([content,color,size])#将每条评论信息添加到列表中 time.sleep(3) #延迟时间,防止太快,被封ip save(lst) #存储到excel中 def save(lst): wk=openpyxl.Workbook() #创建工作簿对象(即使一个.xlsx文件) sheet=wk.active #获取活动表 #遍历列表,把数据添加到工作表中,列表中的数据在excel中是一行 for item in lst: sheet.append(item) wk.save('销售数据.xlsx') #测试 if __name__=='__main__': productId='30890079142' getInfo(productId)
进行数据分析
#数据分析 #分析不同码数鞋子的销量 import openpyxl import matplotlib.pyplot as pit wk=openpyxl.load_workbook('销售数据.xlsx') sheet=wk.active #获取活动sheet表 #获取最大行数和最大列数 row=sheet.max_row col=sheet.max_column #print(row,col) lst=[] #用于存出鞋码 #读取鞋码 for i in range(1,row+1): size=sheet.cell(i,3).value #cell表示sheet的单元格 lst.append(size) #开始统计数据,统计不同码数鞋子的销量 #使用字典,鞋码作键,销量作值 dicSize={} for item in lst: dicSize[item]=0 for item in lst: dicSize[item]=dicSize[item]+1 #输出数据 #for item in dicSize: # print(item,dicSize[item]) lst_total=[] for item in dicSize: lst_total.append([item,dicSize[item],dicSize[item]/100*1.0]) for item in lst_total: print(item) #进行可视化数据统计 labels=[item[0] for item in lst_total] #使用列表生成式 fraces=[item[2] for item in lst_total] pit.rcParams['font.family']=['SimHei']#适应中文 pit.pie(x=fraces,labels=labels,autopct='%1.1f%%') #pit.show() pit.savefig('图.png')#savefig要放在show前面执行,不然会显示空白
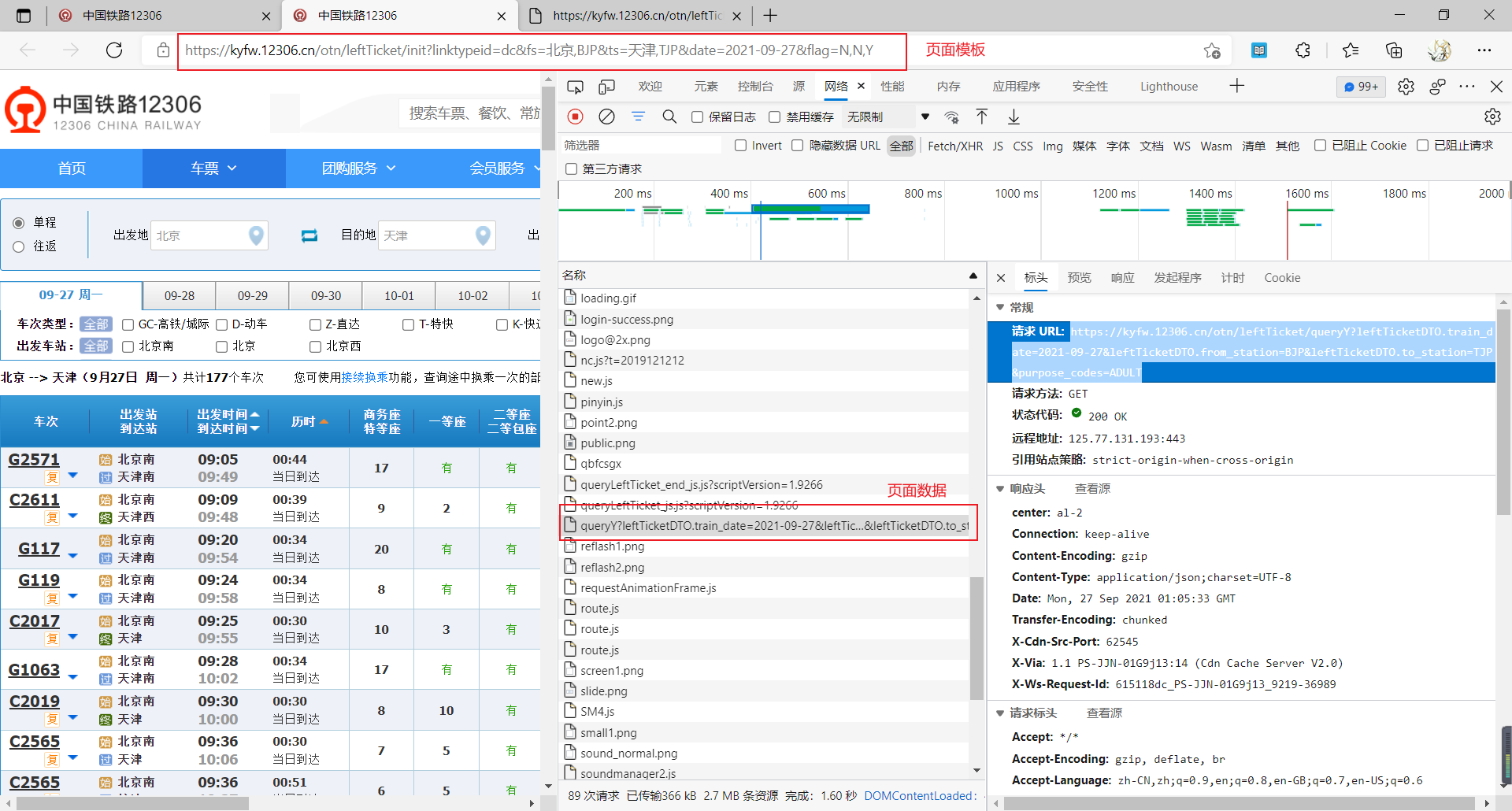
爬取12306车次信息
chrome分析网站elements:元素HTML,css,jsconsoleSource:相当于文件夹,elements,js,css等network:所有发送的请求
如何爬取数据
功能封装函数提取
爬取12306车次数据
- 爬取车次数据后发现车站名称有英文简称,在
js栏中可以找到station_name进行分析
- 爬取车次数据后发现车站名称有英文简称,在
json数据解析正则表达式提取数据
[\u4e00-\u9fa5]代表全部的汉字
数据展示
完整代码
import requests import re #代替浏览器发送请求 def sendRequset(): url='https://kyfw.12306.cn/otn/leftTicket/queryY?leftTicketDTO.train_date=2021-09-27&leftTicketDTO.from_station=BJP&leftTicketDTO.to_station=TJP&purpose_codes=ADULT' headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36 Edg/94.0.992.31','Cookie':'_uab_collina=163270470989732643680974; JSESSIONID=3B9AFBC05E0BD1CD80AF6BC2C261E466; BIGipServerotn=3990290698.50210.0000; BIGipServerpassport=803733770.50215.0000; guidesStatus=off; highContrastMode=defaltMode; cursorStatus=off; RAIL_EXPIRATION=1633025496474; RAIL_DEVICEID=r-BfdT9ZoSUFu8mDnx4vo8tqNI_FJsOg_yhnqUn4X8my8cVtiZS9YdNYxKHeftzfftX-chAnhrrTxEkcbpG5DpiXJ0U4s-Rcyz5-LYa9cQZUGZLQ4H97ygypQeuIMbEXk9CYRijmQRQBzFi90NDhwsXfWvTbT43k; route=9036359bb8a8a461c164a04f8f50b252; _jc_save_fromStation=%u5317%u4EAC%2CBJP; _jc_save_toStation=%u5929%u6D25%2CTJP; _jc_save_fromDate=2021-09-27; _jc_save_toDate=2021-09-27; _jc_save_wfdc_flag=dc; BIGipServerportal=3168010506.17695.0000'} resp=requests.get(url,headers=headers)#加headers的UA后仍然被反爬,再加cookie后得到正确数据,如果还不行则继续加headers #设置编码格式,在网站element栏搜索charset找出编码格式 resp.encoding='utf-8' #print(resp.text) return resp #提取车次信息具体数据 def parseJson(resp,stationName): #将响应结果转为json jsonTicket=resp.json() lstTicket=jsonTicket['data']['result']#提取车次列表 #遍历每个车次信息,以“|”为分隔符分割 #[3]表示车次,[6]查询起始站,[7]查询到达站,[31]一等座,[30]表示二等座,[13]表示出行时间 lst=[]#存储上述信息 for item in lstTicket: d=item.split(sep='|') lst.append([d[3],stationName[d[6]],stationName[d[7]],d[31],d[30],d[13]]) return lst #获取车站名称信息,即’车站名‘和’车站名简称‘的对应表 def getStation(): url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9204' headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36 Edg/94.0.992.31'} resp=requests.get(url,headers=headers) resp.encoding='utf-8' #print(resp.text) #获取指定格式的字串 stationList=re.findall(r'([\u4e00-\u9fa5]+)\|([A-Z]+)',resp.text)#正则表达式,[\u4e00-\u9fa5]代表全部的汉字 #print(stationList) #返回的stationList是列表,需要转成字典 nameDic=dict(stationList) #print(nameDic) #进行键值呼唤 anti_nameDic={} #空字典,用于将key和value进行交换 for item in nameDic: anti_nameDic[nameDic[item]]=item return anti_nameDic def start(): #得到车次信息 lst=parseJson(sendRequset(),getStation()) #筛选,去除无票车次 for item in lst: if item[3]!='无' and item[3]!='': print(item) if __name__ == '__main__': #getStation() start()